MySQL 简述聚簇索引和非聚簇索引
聚集索引与非聚集索引的区别是:叶节点是否存放一整行记录。
聚簇索引的叶节点就是数据节点,而非聚簇索引的叶节点仍然是索引节点,并保留一个链接指向对应数据块。
下图形象的说明了聚簇索引表(InnoDB)和非聚簇索引(MyISAM)的区别:
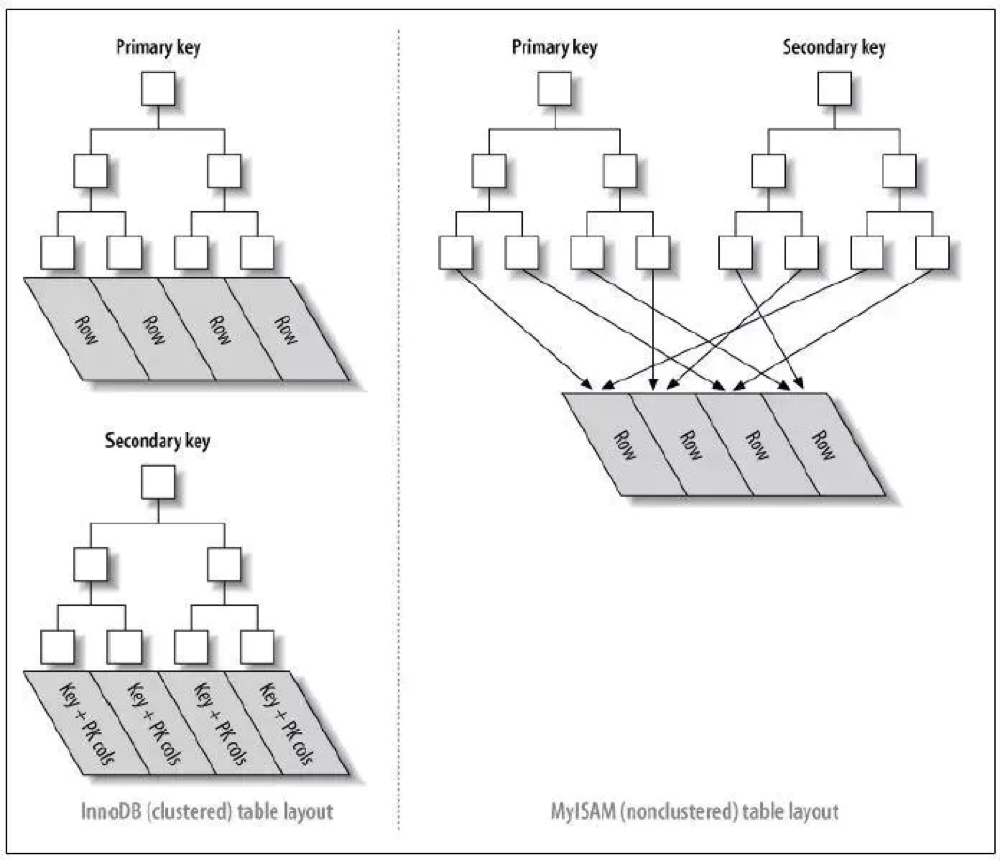
MyISAM的是非聚簇索引,B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上。
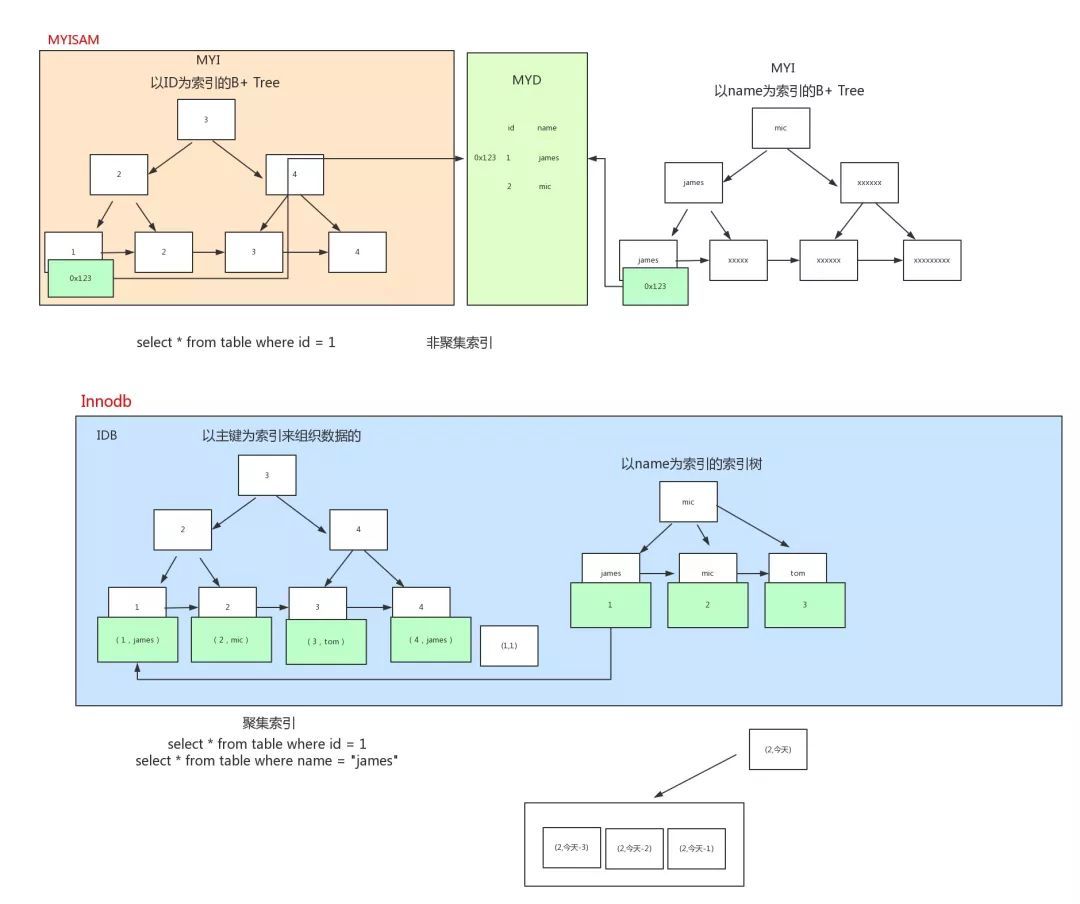
MySQL InnoDB一定会建立聚簇索引,把实际数据行和相关的键值保存在一块,这也决定了一个表只能有一个聚簇索引
-
InnoDB通常根据主键值(primary key)进行聚簇
-
如果没有创建主键,则会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引
-
上面二个条件都不满足,InnoDB会自己创建一个虚拟的聚集索引
聚簇索引的
优点:就是提高数据访问性能。
缺点:维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(page split)的时候。